Intersections, Zonal Statistics, and Distance
Conservation Suitability in Florida
Lesson 5 with Benoit Parmentier
Contents
#################################### Suitability Analysis #######################################
############################ Selection of parcels for conservation #######################################
# This script performs basic analyses for the Exercise 3 of the workshop using Florida data.
# The overall goal is to perform a multi-criteria/sustainabiltiy analysis to select areas suitable
# for conservation.
#
#Goal: Determine the ten (10) parcels of land within Clay County in the focus zone most suitable for purchase
#towards conversion to land conservation.
#
#AUTHORS: Benoit Parmentier
#DATE CREATED: 03/17/2017
#DATE MODIFIED: 04/02/2018
#Version: 2
#PROJECT: SESYNC and AAG 2018 workshop/Short Course preparation
#TO DO:
#
#COMMIT: testing code on virtual machine, AAG workshop
#
#################################################################################################
###Loading R library and packages
library(sp) # spatial/geographfic objects and functions
library(rgdal) #GDAL/OGR binding for R with functionalities
rgdal: version: 1.2-18, (SVN revision 718)
Geospatial Data Abstraction Library extensions to R successfully loaded
Loaded GDAL runtime: GDAL 2.1.3, released 2017/20/01
Path to GDAL shared files: /usr/share/gdal/2.1
GDAL binary built with GEOS: TRUE
Loaded PROJ.4 runtime: Rel. 4.9.2, 08 September 2015, [PJ_VERSION: 492]
Path to PROJ.4 shared files: (autodetected)
Linking to sp version: 1.2-7
library(spdep) #spatial analyses operations, functions etc.
Loading required package: Matrix
Loading required package: spData
To access larger datasets in this package, install the spDataLarge
package with: `install.packages('spDataLarge',
repos='https://nowosad.github.io/drat/', type='source'))`
library(gtools) # contains mixsort and other useful functions
library(maptools) # tools to manipulate spatial data
Checking rgeos availability: TRUE
#library(parallel) # parallel computation, part of base package no
library(rasterVis) # raster visualization operations
Loading required package: raster
Loading required package: lattice
Loading required package: latticeExtra
Loading required package: RColorBrewer
library(raster) # raster functionalities
library(forecast) #ARIMA forecasting
library(xts) #extension for time series object and analyses
Loading required package: zoo
Attaching package: 'zoo'
The following objects are masked from 'package:base':
as.Date, as.Date.numeric
library(zoo) # time series object and analysis
library(lubridate) # dates functionality
Attaching package: 'lubridate'
The following object is masked from 'package:base':
date
library(colorRamps) #contains matlab.like color palette
library(rgeos) #contains topological operations
rgeos version: 0.3-26, (SVN revision 560)
GEOS runtime version: 3.5.1-CAPI-1.9.1 r4246
Linking to sp version: 1.2-5
Polygon checking: TRUE
library(sphet) #contains spreg, spatial regression modeling
Attaching package: 'sphet'
The following object is masked from 'package:raster':
distance
library(BMS) #contains hex2bin and bin2hex, Bayesian methods
library(bitops) # function for bitwise operations
library(foreign) # import datasets from SAS, spss, stata and other sources
library(gdata) #read xls, dbf etc., not recently updated but useful
gdata: read.xls support for 'XLS' (Excel 97-2004) files ENABLED.
gdata: read.xls support for 'XLSX' (Excel 2007+) files ENABLED.
Attaching package: 'gdata'
The following objects are masked from 'package:xts':
first, last
The following objects are masked from 'package:raster':
resample, trim
The following object is masked from 'package:stats':
nobs
The following object is masked from 'package:utils':
object.size
The following object is masked from 'package:base':
startsWith
library(classInt) #methods to generate class limits
library(plyr) #data wrangling: various operations for splitting, combining data
Attaching package: 'plyr'
The following object is masked from 'package:lubridate':
here
#library(gstat) #spatial interpolation and kriging methods
library(readxl) #functionalities to read in excel type data
###### Functions used in this script
#function_preprocessing_and_analyses <- "fire_alaska_analyses_preprocessing_functions_03102017.R" #PARAM 1
#script_path <- "/home/attendee/data/AAG2017_spatial_temporal_analysis_R/R_scripts"
#source(file.path(script_path,function_preprocessing_and_analyses)) #source all functions used in this script 1.
create_dir_fun <- function(outDir,out_suffix=NULL){
#if out_suffix is not null then append out_suffix string
if(!is.null(out_suffix)){
out_name <- paste("output_",out_suffix,sep="")
outDir <- file.path(outDir,out_name)
}
#create if does not exists
if(!file.exists(outDir)){
dir.create(outDir)
}
return(outDir)
}
##### Parameters and argument set up ###########
in_dir_var <- "../data"
out_dir <- "."
strat_hab_fname <- "Strat_hab_con_areas1" #1)Strategic Habitat conservation areas raster file
regional_counties_fname <- "Regional_Counties" #2) County shapefile
roads_fname <- "roads_counts" #3) Roads count raster
priority_wet_habitats_fname <- "Priority_Wet_Habitats1" #4) Priority Wetlands Habitat raster file
clay_parcels_fname <- "Clay_Parcels" #5) Clay County parcel shapefile
habitat_fname <- "Habitat" #6) General Habitat raster file
biodiversity_hotspot_fname <- "Biodiversity_Hot_Spots1" #7) Biodiversity hotspot raster file
florida_managed_areas_fname <- "flma_jun13" #8) Florida managed areas shapefile
focus_zone1_fname <- "focus_zone1" #9) focus zone as raster file
##Additional data:
#roads_distance_exercise3.tif: distance to roads
#r_flma_clay_bool_distance_exercise3.tif: distance to Florida Mangement Areas
gdal_installed <- FALSE #if true use the system/shell command else use the distance layer provided
file_format <- ".tif" #PARAM5
NA_flag_val <- -9999 #PARAM7
out_suffix <-"exercise3_04022018" #output suffix for the files and ouptu folder #PARAM 8
create_out_dir_param=TRUE #PARAM9
################# START SCRIPT ###############################
## First create an output directory
if(is.null(out_dir)){
out_dir <- dirname(in_dir) #output will be created in the input dir
}
out_suffix_s <- out_suffix #can modify name of output suffix
if(create_out_dir_param==TRUE){
out_dir <- create_dir_fun(out_dir,out_suffix_s)
setwd(out_dir)
}else{
setwd(out_dir) #use previoulsy defined directory
}
#### PART I: EXPLORE DATA READ AND DISPLAY INPUTS #######
##Inputs:
#1) Strategic Habitat conservation areas raster file
#2) County shapefile
#3) Roads shapefile
#4) Priority Wetlands Habitat raster file
#5) Clay County parcel shapefile
#6) General Habitat raster file
#7) Biodiversity hotspot raster file
#8) Florida managed areas shapefile
#9) Focus area as raster file
## Read in the datasets
r_strat_hab <- raster(file.path(in_dir_var,strat_hab_fname,paste(strat_hab_fname,"tif",sep=".")))
reg_counties_sp <- readOGR(dsn=in_dir_var,regional_counties_fname)
OGR data source with driver: ESRI Shapefile
Source: "/nfs/public-data/training", layer: "Regional_Counties"
with 9 features
It has 9 fields
r_roads <- raster(file.path(in_dir_var,roads_fname,paste(roads_fname,"tif",sep=".")))
r_priority_wet_hab <- raster(file.path(in_dir_var,priority_wet_habitats_fname,paste(priority_wet_habitats_fname,"tif",sep=".")))
clay_sp <- readOGR(dsn=in_dir_var, clay_parcels_fname) #large file
OGR data source with driver: ESRI Shapefile
Source: "/nfs/public-data/training", layer: "Clay_Parcels"
with 84601 features
It has 139 fields
r_habitat <- raster(file.path(in_dir_var,habitat_fname,paste(habitat_fname,"tif",sep=".")))
r_bio_hotspot <- raster(file.path(in_dir_var,biodiversity_hotspot_fname,paste(biodiversity_hotspot_fname,"tif",sep=".")))
flma_sp <- readOGR(dsn=in_dir_var,florida_managed_areas_fname)
OGR data source with driver: ESRI Shapefile
Source: "/nfs/public-data/training", layer: "flma_jun13"
with 2220 features
It has 33 fields
r_focus_zone1 <- raster(file.path(in_dir_var,focus_zone1_fname,paste(focus_zone1_fname,"tif",sep=".")))
## Visualize a few datasets
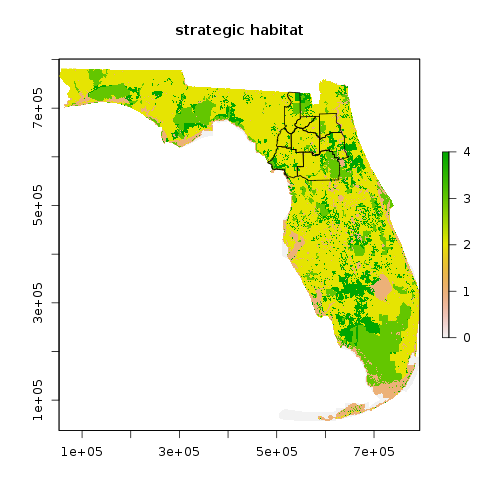
plot(r_strat_hab, main="strategic habitat")
plot(reg_counties_sp,add=T)
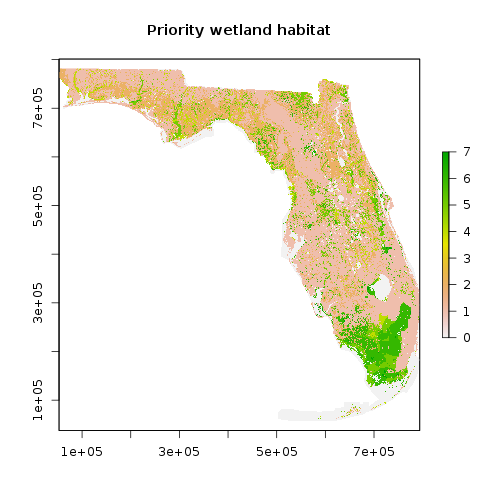
plot(r_priority_wet_hab, main="Priority wetland habitat")
#plot(r_habitat,add=T)
##### Before starting the production of the sustainability factor let's check the projection,
#resolution for each layer relevant to the calculation
#raster layers:
list_raster <- c(r_strat_hab,r_priority_wet_hab,r_habitat,r_bio_hotspot)
## Examine information on rasters using lapply
lapply(list_raster,function(x){res(x)}) #spatial resolution
[[1]]
[1] 55 55
[[2]]
[1] 225 225
[[3]]
[1] 62.63 62.63
[[4]]
[1] 100 100
lapply(list_raster,function(x){projection(x)}) #spatial projection
[[1]]
[1] "+proj=aea +lat_1=24 +lat_2=31.5 +lat_0=24 +lon_0=-84 +x_0=400000 +y_0=0 +ellps=GRS80 +units=m +no_defs"
[[2]]
[1] "+proj=aea +lat_1=24 +lat_2=31.5 +lat_0=24 +lon_0=-84 +x_0=400000 +y_0=0 +ellps=GRS80 +units=m +no_defs"
[[3]]
[1] "+proj=aea +lat_1=24 +lat_2=31.5 +lat_0=24 +lon_0=-84 +x_0=400000 +y_0=0 +ellps=GRS80 +units=m +no_defs"
[[4]]
[1] "+proj=aea +lat_1=24 +lat_2=31.5 +lat_0=24 +lon_0=-84 +x_0=400000 +y_0=0 +ellps=GRS80 +units=m +no_defs"
lapply(list_raster,function(x){extent(x)}) #extent of rasters
[[1]]
class : Extent
xmin : 52650.4
xmax : 793995.4
ymin : 56824.82
ymax : 781614.8
[[2]]
class : Extent
xmin : 52650.39
xmax : 794025.4
ymin : 56824.82
ymax : 781774.8
[[3]]
class : Extent
xmin : 481073.7
xmax : 648609
ymin : 551568.7
ymax : 732882.6
[[4]]
class : Extent
xmin : 52650.39
xmax : 793950.4
ymin : 56824.82
ymax : 781624.8
### PART 0: generate reference layer
## Let's use the resolution 55x55 m as the reference since it corresponds to finer resolution relevant
# for this study. The focus region provides the extent for the final step.
## Select clay county
clay_county_sp <- subset(reg_counties_sp,NAME=="CLAY")
plot(r_strat_hab, main="strategic habitat")
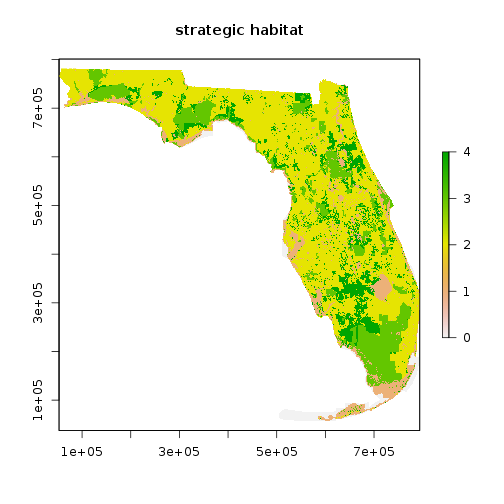
## Crop r_strat_hab
r_ref <- crop(r_strat_hab,clay_county_sp) #make a reference image for use in the processing
plot(r_ref)
plot(clay_county_sp,border="red",add=T)
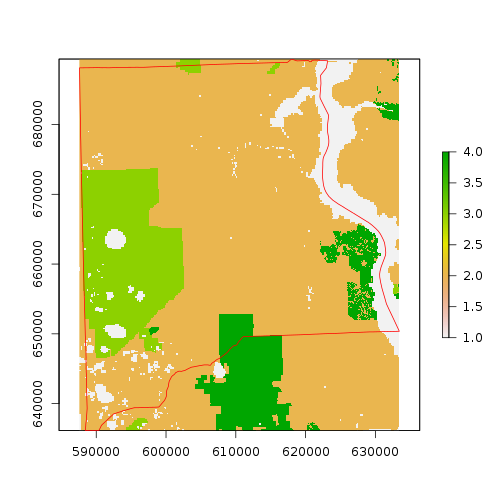
r_clay <- rasterize(clay_county_sp,r_ref) #this can be used as mask for the study area
freq(r_clay) #check the distribution of values: 1 and NA
value count
[1,] 1 551163
[2,] NA 256149
##Use raster of Clay county definining the study area to mask pixels
plot(r_clay)
dim(r_clay) #number of rows and columns as well as number of layers/bands
[1] 968 834 1
#### PART II : HIGH BIODIVERSITY SUITABILITY LAYERS #######
## IDENTIFY LANDS WITH HIGH NATIVE BIODIVERSITY
### STEP 1: Strategic Habitat conservation areas
#Input data layer: Habitat
#We will use information from the National Heritage Froundation to reclassify the Habitat layer as input
#criterion for the suitability analysis.
#Criteria for value assignment: Habitat ranked by the Natural Heritage Program as having high native
#biodiversity were given a value of 9. Habitat ranked as having a moderate native biodiversity were given
#a value of 5, and all other habitat types were given a value of 1.
#Rationale for value assignment: Certain habitat types are known to have higher native biodiversity than
#others, consequently those with higher native biodiversity were given higher suitability rankings.
#Output: Habitat Biodiversity
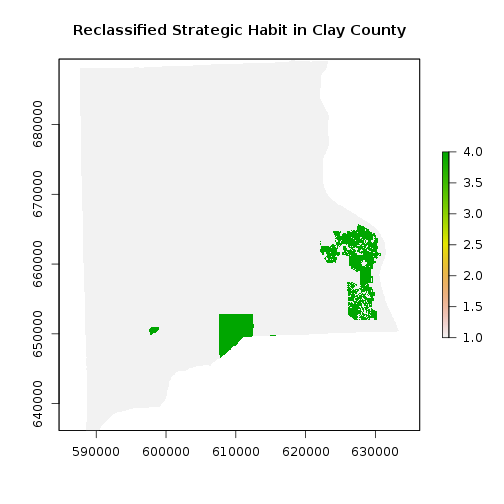
#strategic habitat conservation areas
r_strat_hab_w <- crop(r_strat_hab,r_clay) #Crop habitat conservation layer covering the State of Florida
r_strat_hab_masked <- mask(r_strat_hab_w,r_clay) # Mask layer matching the Clay county area
## Now reclassify: create a matrix of reclassification
#values are: from, to, assigned value
m <- c(5, 1000, 9, #use 1000 as upper limit, can be any value greater than max
4, 5, 5,
1, 3, 1)
rclmat <- matrix(m, ncol=3, byrow=TRUE)
#?raster::reclassify: to find out information on the function
rc_strat_hab_reg <- reclassify(r_strat_hab_masked, rclmat)
plot(rc_strat_hab_reg,main="Reclassified Strategic Habit in Clay County")
### STEP 2: Identify Lands With High Native Biodiversity based on species count
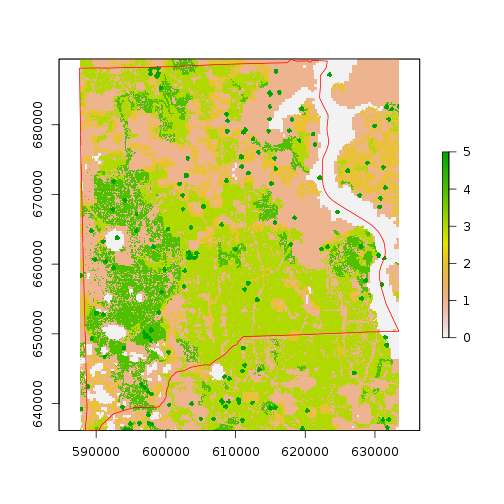
## Crop bio raster
r_bio_hotspot_w <- crop(r_bio_hotspot,clay_county_sp)
plot(r_bio_hotspot_w)
plot(clay_county_sp,border="red",add=T)
#r_bio_clay_masked <- mask(r_bio_hotspot_w,r_clay) ## Does not work!! because resolution don't match
#match resolution:
projection(r_bio_hotspot_w)==projection(r_clay) #projection match
[1] TRUE
res(r_bio_hotspot_w)==res(r_clay) #the resolutions do not match, we will need to resample
[1] FALSE FALSE
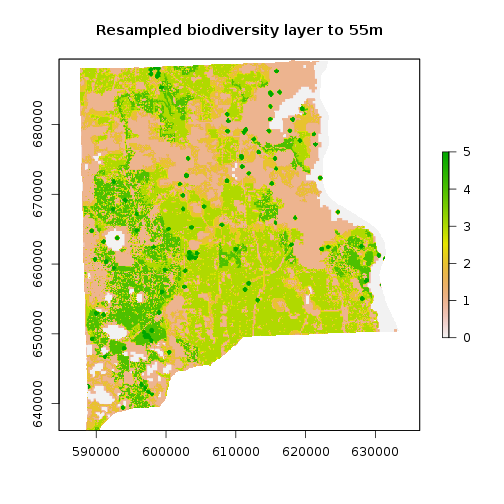
## Find about resample
#?raster::resample #to find out about the resample function from the raster package
r_bio_hotspot_reg <- raster::resample(x=r_bio_hotspot_w,y=r_clay, method="bilinear") #Use resample to match resolutions
r_bio_hotspot_reg <- mask(r_bio_hotspot_reg,r_clay) ## It now works because resolutions were matched
plot(r_bio_hotspot_reg,main="Resampled biodiversity layer to 55m")
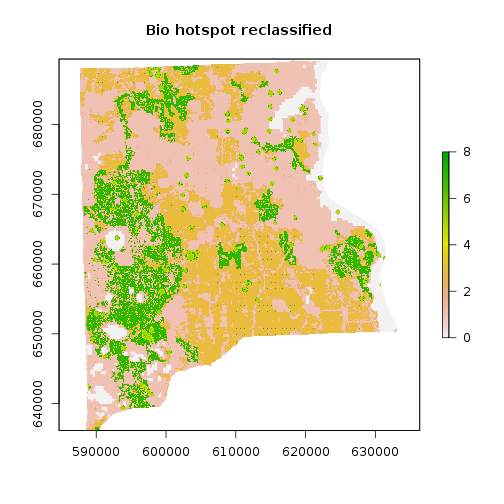
### Reclassify using instructions/information given to us:
m <- c(9, 1000, 9,
5, 8, 8,
3, 4, 7,
1, 2,1)
rclmat <- matrix(m, ncol=3, byrow=TRUE)
rc_bio_hotspot_reg <- reclassify(r_bio_hotspot_reg, rclmat)
plot(rc_bio_hotspot_reg, main="Bio hotspot reclassified")
### STEP 3: Wetland priority
#Input data layer: Priority Wetland Habitats
#Criteria for value assignment: Values were assigned based on the number of focal species present in
#each cell. The value of 9 was assigned to 10–12 wetland focal species, 8 was assigned to 7–9 wetland focal
#species, 7 was assigned to 4–6 wetland focal species and 4–6 upland focal species, 6 was assigned to
#1–3 wetland or upland focal species. The value 1 was assigned to all other cells.
#Rationale for value assignment: The better the habitat for focal wetland species, the higher the priority.
#Output: Wetland Biodiversity
#check projection
projection(r_priority_wet_hab)
[1] "+proj=aea +lat_1=24 +lat_2=31.5 +lat_0=24 +lon_0=-84 +x_0=400000 +y_0=0 +ellps=GRS80 +units=m +no_defs"
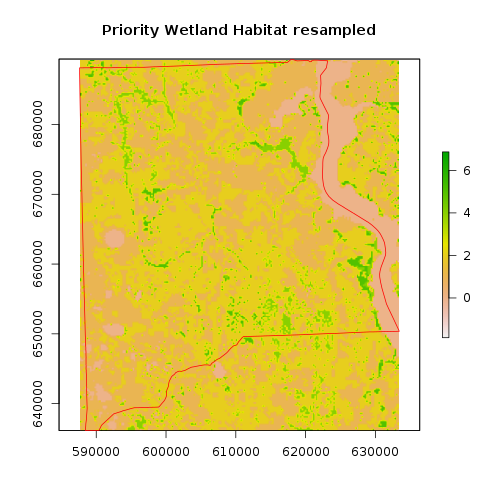
## Crop Wetland priority raster
r_priority_wet_hab_w <- crop(r_priority_wet_hab,clay_county_sp)
#r_priority_wet_hab_reg <- mask(r_priority_wet_hab_w,r_clay) ## Does not work!! because resolution don't match
#match resolution:
r_priority_wet_hab_reg <- raster::resample(r_priority_wet_hab_w,r_clay, method='bilinear') #resolution matching the study region
#r_priority_wet_hab_reg <- mask(r_priority_wet_hab_reg,r_clay) ## Does not work!! because resolution don't match
plot(r_priority_wet_hab_reg,main="Priority Wetland Habitat resampled")
plot(clay_county_sp,border="red",add=T)
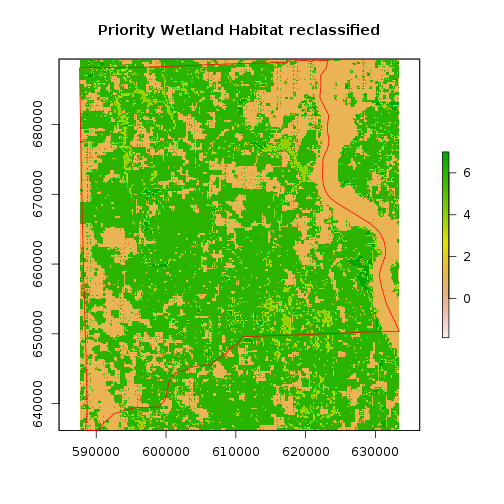
### Now reclass
#The value of 9 was assigned to 10–12 wetland focal species, 8 was assigned to 7–9 wetland focal
#species, 7 was assigned to 4–6 wetland focal species and 4–6 upland focal species, 6 was assigned to
#1–3 wetland or upland focal species. The value 1 was assigned to all other cells.
m <- c(10, 12, 9,
7, 9, 8,
4, 6, 7,
1, 3,6,
-1, 1,1)
rclmat <- matrix(m, ncol=3, byrow=TRUE)
rc_priority_wet_hab_reg <- reclassify(r_priority_wet_hab_reg, rclmat)
freq_tb <- freq(rc_priority_wet_hab_reg)
freq_tb
value count
[1,] -2 4
[2,] -1 6
[3,] 1 250708
[4,] 3 19603
[5,] 4 22097
[6,] 6 498078
[7,] 7 12250
[8,] NA 4566
plot(rc_priority_wet_hab_reg,main="Priority Wetland Habitat reclassified")
plot(clay_county_sp,border="red",add=T)
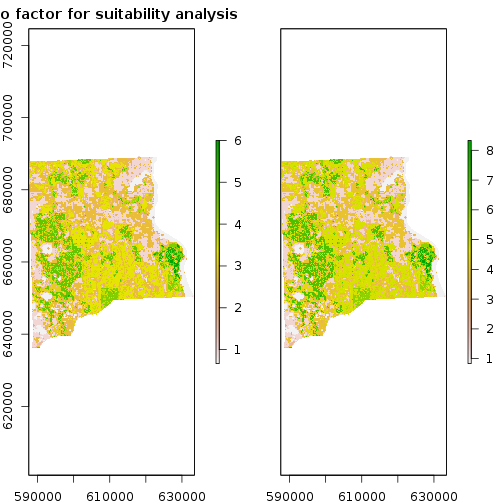
### STEP 4: Combine all the three input criteria layers with weigthed/unweighted sum
f_weights <- c(1,1,1)/3
r_bio_es_factor <- (f_weights[1]*rc_strat_hab_reg + f_weights[2]*rc_bio_hotspot_reg + f_weights[3]*rc_priority_wet_hab_reg) #weighted sum
f_weights <- c(1,1.5,1.5)/3
r_bio_ws_factor <- (f_weights[1]*rc_strat_hab_reg + f_weights[2]*rc_bio_hotspot_reg + f_weights[3]*rc_priority_wet_hab_reg) #weighted sum
r_bio_factor <- stack(r_bio_es_factor,r_bio_ws_factor)
names(r_bio_factor) <- c("equal_weights","weigthed_sum")
#plot(r_bio_factor,main="Bio factor for suitability analysis")
plot(r_bio_factor)
out_suffix_str <- paste0(names(r_bio_factor),"_",out_suffix) # this needs to be matching the number of outputs files writeRaste
##Write out raster file:
writeRaster(r_bio_factor,filename="r_bio_factor_clay.tif",
bylayer=T,datatype="FLT4S",options="COMPRESS=LZW",suffix=out_suffix_str,overwrite=T)
#### PART III : SUITABILITY LAYERS #######
#IDENTIFY POTENTIAL CONSERVATION LANDS IN RELATION WITH DISTANCE TO ROADS AND EXISTING MANAGED LANDS
#GOAL: Create two raster maps showing lands in Clay County,
#Florida that have would have higher conservation potential based on
#local road density and distance from existing managed lands using a combination
#of the Clip, Extract by Mask, Euclidean Distance, Line Density, Project, Reclassify, and Weighted Sum tools.
#Step 1: prepare files to create a distance to road layer
### Processs roads first
plot(r_roads,main="Roads_count in Clay county")
r_roads_bool <- r_roads > 0
NAvalue(r_roads_bool ) <- 0
roads_bool_fname <- file.path(out_dir,paste0("roads_bool_",out_suffix,file_format))
r_roads_bool <- writeRaster(r_roads_bool,filename=roads_bool_fname,overwrite=T)
Error in .local(x, filename, ...): Attempting to write a file to a path that does not exist:
./output_exercise3_04022018
#setp 2: prepare files to create a distance to existing managed land
r_flma_clay <- rasterize(flma_sp,r_clay,"OBJECTID_1",fun="max")
r_flma_clay_bool <- r_flma_clay > 0
NAvalue(r_flma_clay_bool) <- 0
r_flma_clay_bool_fname <- file.path(out_dir,paste0("r_flma_clay_bool_",out_suffix,file_format))
r_flma_clay_bool <- writeRaster(r_flma_clay_bool,filename=r_flma_clay_bool_fname,overwrite=T)
Error in .local(x, filename, ...): Attempting to write a file to a path that does not exist:
./output_exercise3_04022018
plot(r_flma_clay_bool,"Management areas in Clay County")
plot(clay_county_sp,border="red",add=T)
if(gdal_installed==TRUE){
## Roads
srcfile <- roads_bool_fname
dstfile_roads <- file.path(out_dir,paste("roads_distance_",out_suffix,file_format,sep=""))
n_values <- "1"
### Note that gdal_proximity doesn't like when path is too long
cmd_roads_str <- paste("gdal_proximity.py",basename(srcfile),basename(dstfile_roads),"-values",n_values,sep=" ")
#cmd_str <- paste("gdal_proximity.py", srcfile, dstfile,sep=" ")
### Prepare command for FLMA
srcfile <- r_flma_clay_bool_fname
dstfile_flma <- file.path(out_dir,paste("r_flma_clay_bool_distance_",out_suffix,file_format,sep=""))
n_values <- "1"
### Note that gdal_proximity doesn't like when path is too long
cmd_flma_str <- paste("gdal_proximity.py",basename(srcfile),basename(dstfile_flma),"-values",n_values,sep=" ")
#cmd_str <- paste("gdal_proximity.py", srcfile, dstfile,sep=" ")
sys_os <- as.list(Sys.info())$sysname
if(sys_os=="Windows"){
shell(cmd_roads_str)
shell(cmd_flma_str)
}else{
system(cmd_roads_str)
system(cmd_flma_str)
}
r_flma_distance <- raster(dstfile_flma)
r_roads_distance <- raster(dstfile_roads)
}else{
r_roads_distance <- raster(file.path(in_dir_var,"additional_data",paste("roads_distance_exercise3",file_format,sep="")))
r_flma_distance <- raster(file.path(in_dir_var,"additional_data",paste("r_flma_clay_bool_distance_exercise3",file_format,sep="")))
}
#Now rescale the distance...
min_val <- cellStats(r_roads_distance,min)
max_val <- cellStats(r_roads_distance,max)
#Linear rescaling:
#y = ax + b with b=0
#with 9 being new max and 0 being new min
a = (9 - 0) /(max_val - min_val)
r_roads_dist <- r_roads_distance * a
#Get distance from managed land
#b. Which parts of Clay County contain proximity-to-managed-lands characteristics that would make them more favorable to be used as conservation lands?
min_val <- cellStats(r_flma_distance,min)
max_val <- cellStats(r_flma_distance,max)
a = (9 - 0) /(max_val - min_val) #linear rescaling factor
r_flma_dist <- r_flma_distance * a
#### PART IV : COMBINE FACTORS AND DETERMINE MOST SUITABLE PARCELS #######
#IDENTIFY POTENTIAL CONSERVATION LANDS IN RELATION TO PARCEL SUITABILITY
#GOAL: Create two raster maps showing parcels in Clay County, Florida that have would
#have higher conservation potential based on parcel values.
#First, factors must be combined to generate a suitability index.
### Step 1: Combine distance factors with weights...
f_weights <- c(1,1)/2 #factor weights for distance to roads
r_dist_factor <- f_weights[1]*r_roads_dist + f_weights[2]*r_flma_dist #weighted sum with equal weight
### Step 3: Combine distance factor and bio factor
f_weights <- c(2/3,1/3) #We are weighting factor bio more for this exercise
r_suitability_factor <- f_weights[1]*r_bio_factor + f_weights[2]*r_dist_factor #weighted sum with equal weight
names(r_suitability_factor) <- c("suitability1","suitability2")
plot(r_suitability_factor)
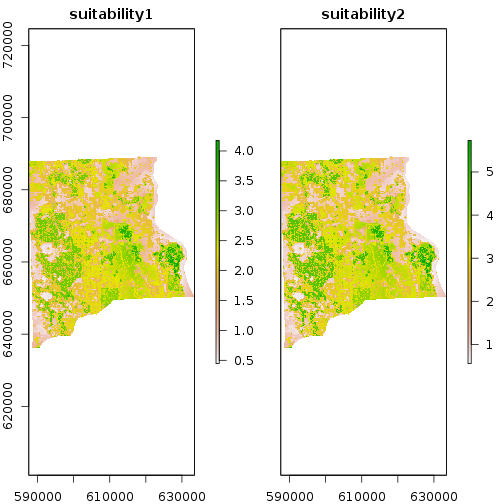
out_suffix_str <- paste0(names(r_suitability_factor),"_",out_suffix) # this needs to be matching the number of outputs files writeRaste
writeRaster(r_suitability_factor,filename="r_suitability_factor_clay.tif",
bylayer=T,datatype="FLT4S",options="COMPRESS=LZW",suffix=out_suffix_str,overwrite=T)
### Write out later
#writeRaster(,"bio_factor_equal_weights.tif")
#writeRaster(subset(r_bio_factor,1),"bio_factor_equal_weights.tif")
# Step 3: summarize by parcels!!
projection(r_focus_zone1)<- projection(r_clay)
clay_sp_parcels_reg <- spTransform(clay_sp,projection(r_clay))
parcels_focus_zone1_sp <- intersect(clay_sp_parcels_reg,r_focus_zone1)
Warning in intersect(x, y): non identical CRS
parcels_avg_suitability <- extract(r_suitability_factor,parcels_focus_zone1_sp,fun=mean,sp=T)
#spplot(parcels_avg_suitability,"equal_weights")
## Select top 10 parcels to target for conservation
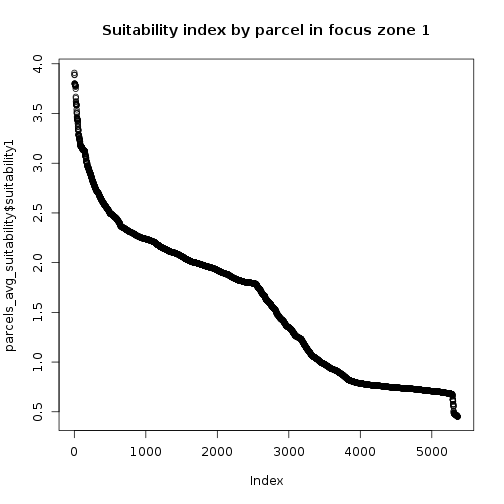
parcels_avg_suitability <- parcels_avg_suitability[order(parcels_avg_suitability$suitability1,decreasing = T),]
plot(parcels_avg_suitability$suitability1,main="Suitability index by parcel in focus zone 1")
p<- spplot(parcels_avg_suitability[1:10,],"suitability1",main="Selected top 10 parcels for possible conservation")
print(p)
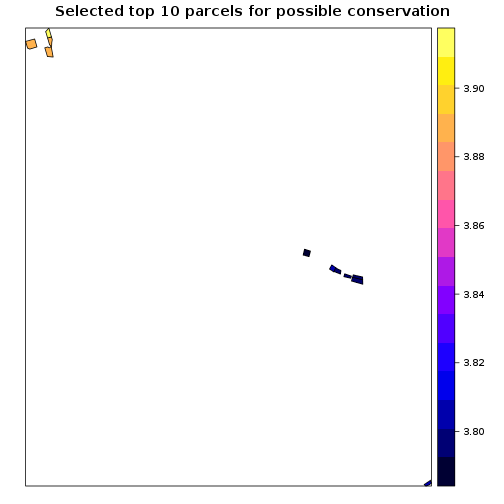
##Figure of selected parcels
plot(clay_county_sp,border="red",main="Selected parcels")
plot(parcels_avg_suitability[1:10,],add=T)
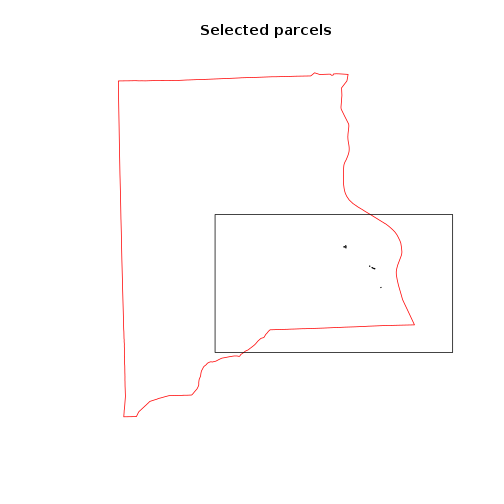
############################## END OF SCRIPT ##########################################